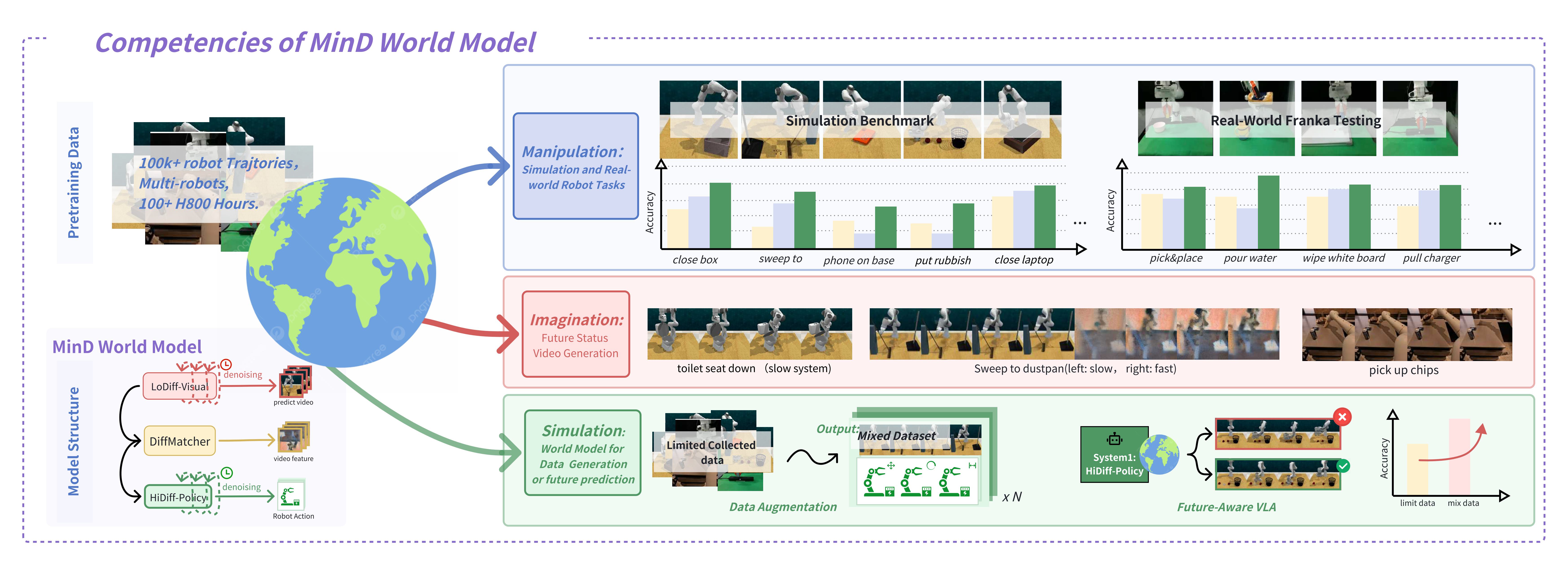
Recently, Video Generation Models (VGMs) have been widely used as feature extraction backbones for VLA models, leveraging internet-scale pretraining for robust dynamics modeling. However, world models are beyond visual representation encoders; existing methods fail to tap into the potential of their powerful distribution modeling capabilities for predicting future states. This oversight stems from two challenges: integrating generative processes into feature learning is technically challenging and conceptually underdeveloped. Moreover, applying generative world models in robotics is challenging—naively generating future frames through video diffusion is computationally inefficient and unsuitable for real-time control.
To address these challenges, we introduce Manipulate in Dream (MinD), a dual-system world model designed for risk-aware planning that enables real-time prediction. MinD runs two asynchronous diffusion processes: a low-frequency visual generator that first creates a future scene, and a high-frequency diffusion policy that then outputs actions. Our key insight is that robotic policies rely not on completely denoised image frames, but instead on low-resolution latents efficiently produced in a single denoising timestep, still serving as an effective future state representation.
To connect this early prediction to actions, we propose a video-action diffusion matching module (DiffMatcher), with a novel co-training strategy that uses separate schedulers for each diffusion model. Specifically, we introduce a diffusion-forcing mechanism to DiffMatcher that aligns their intermediate representations during training, helping the fast action model better understand video-based predictions. Our method achieves a 63\% success rate on RL-Bench, 60\% on real-world Franka with 11.3 FPS, demonstrating that a single-step feature is highly effective for learning control signals. As a significant secondary finding, we demonstrate that MinD can identify 74\% of potential task failures in advance by analyzing generated video clips, while the nascent feature could also serve as an indicator. This provides a valuable, real-time signal for safety monitoring and human intervention.
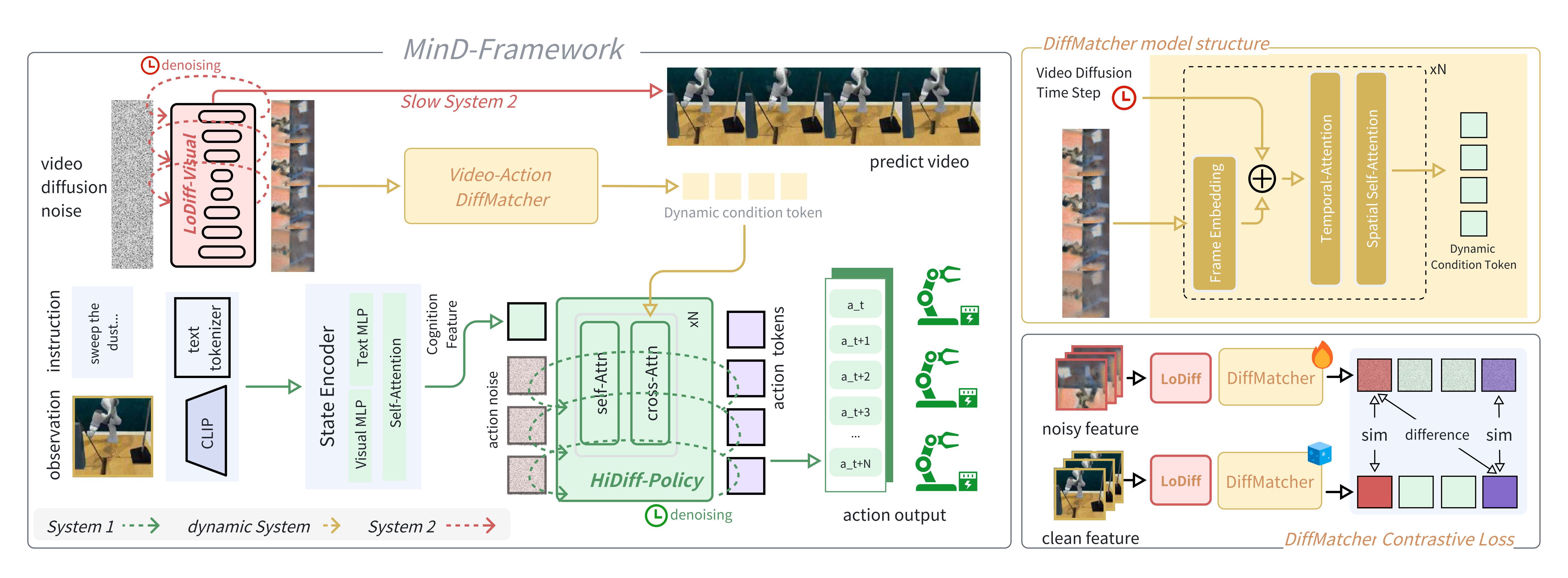
MinD is a general-purpose multimodal world model for robotic manipulation that integrates visual imagination and action planning. Its core consists of a hierarchical diffusion-based framework with three components:
During inference, LoDiff-Visual forward-simulates noisy visual latents, which DiffMatcher transforms into aligned features to condition HiDiff-Policy for action generation. The system is trained with a dual-scheduler co-training strategy, optimizing a total objective that includes a video loss, an action loss, and a regularization loss for DiffMatcher (to enforce consistency between noisy and clean visual features), ensuring robust performance across asynchronous temporal scales and imperfect inputs.

Comparison of video generation result from LoDiff-Visual against real execution observation of HiDiff-Policy of RL-Bench and real-world Franka. |
We first evaluate MinD in the RL-Bench evaluation environment. This simulation platform is a comprehensive robot learning benchmark and environment with 7 tasks designed to advance research in vision-guided robot manipulation with a single-arm Franka Panda robot and a front-view camera. We compare MinD with existing VLA models, including CogACT, RoboMamba, RoboDreamer, π-0, Video Prediction Policy(VPP) and OpenVLA. For the model using Mamba or LLM as the backbone, we colored it with a green background. We use a yellow background for the VLA models with a video generation backbone, and a red background for our method.
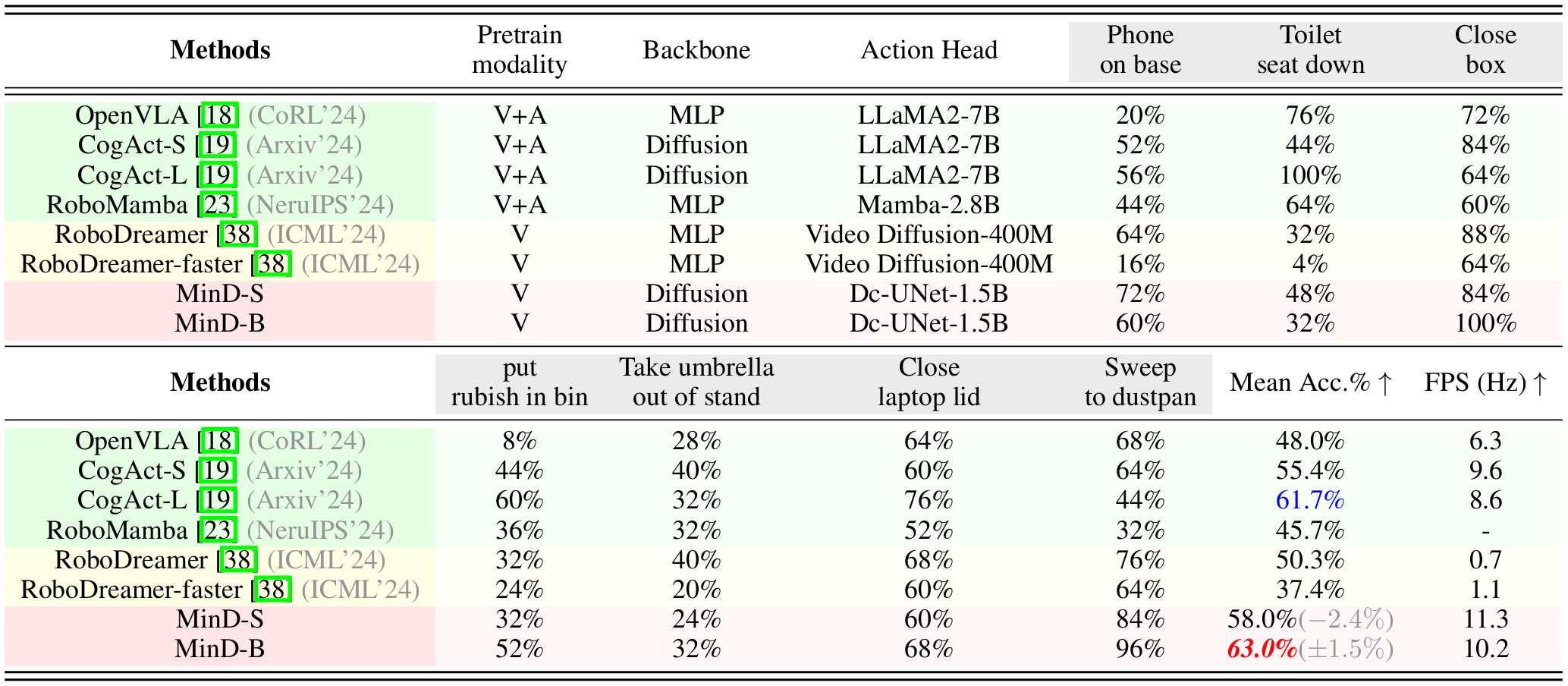
Evaluation and comparison on RL-Bench tasks. All models are finetuned on the collected 1000 trajectories (including 100 trajectories for each 7 tasks and 300 more randomly sampled tasks). |
The results show that MinD outperforms all the existing VLA models, especially in tasks requiring complex temporal reasoning, such as "Sweep to Dustpan" (96%) and "Close Laptop Lid" (68%), highlighting the strong capability of video generation models as the foundational backbone for comprehensive visual-language manipulations. Besides, MinD also achieves a competitive inference speed of 11.3 FPS, showcasing its superior efficiency.
We evaluate MinD with a Franka Research 3 Robot to perform 3 kinds of real-world tasks: 1) a pick-and-place task (e.g., placing a cube into a bowl or a croissant into a basket), 2) unplugging the charger, and 3) wiping the whiteboard}. We collected a dataset with 100 human demonstration trajectories via teleoperation using a SpaceMouse. As shown in the table below, the performance of MinD consistently surpasses those of other VLA models, represented by OpenVLA, and VGM-based world models, such as VPP. Notably, while VPP also shows competitive results on the long-horizon task of wiping whiteboard, our model attains superior performance and operates at a higher control frequency. This is attributed to our DiffMatcher design, which preserves the characteristics of both fast and slow systems, enabling a tighter coupling between prediction and execution.
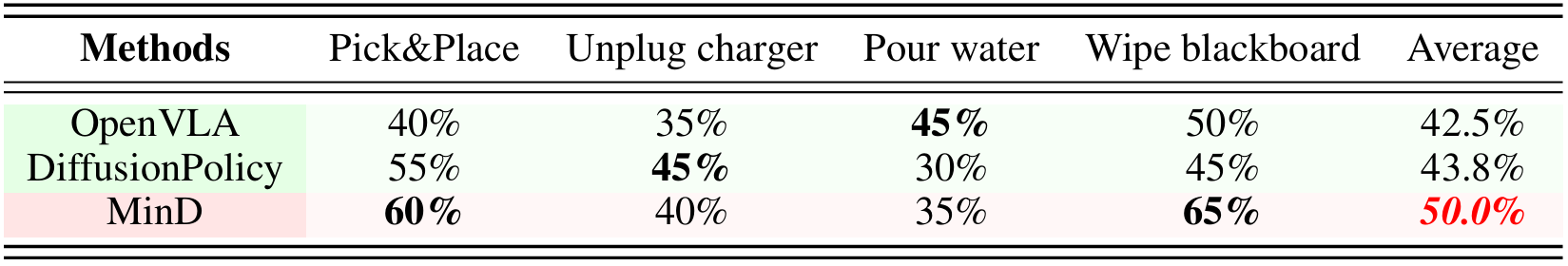
Real-world evaluation with Franka robot across four tasks, each with 20 rollouts using the latest checkpoints across varied tabletop positions |
We evaluate each configuration based on video generation quality (FVD [30]) and success rate (SR) in task execution. The results highlight the impact of key components such as LDP, diffusion modules (LoDiff, DiffMatcher, HiDiff), and loss functions (Lvideo, Lsim, Laction) on performance. It also shows that large-scale video data pretraining and diffusion modules are vital for improving how well our MinD robot framework executes and generates videos. In short, using both video and action data, pretraining, and all the loss functions are key for best results in robot learning.
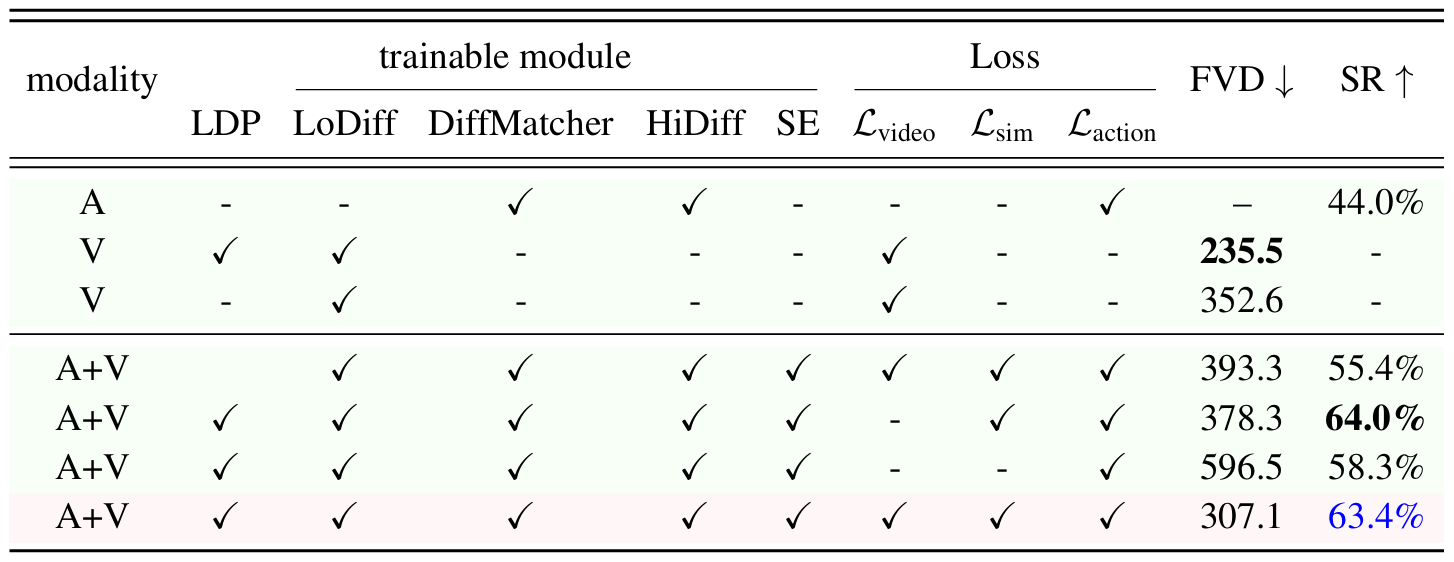
Ablation study results. SE denotes the state encoder, LDP represents large-scale data pretraining, A denotes action and V is video. |
We also conducted case study exploring how video generation models (VGMs) enhance the trustworthiness of world-model-based VLA by enabling risk assessment and outcome prediction for robotic tasks. We demonstrate that VGMs can predict both successful and failed executions, offering actionable insights for safer real-world deployment. Beyond visual inspection and human evaluation, we further analyze the latent features via PCA, a single-step feature that is used for HiDiff-Policy. We observe clear distributional differences between successful and failed predictions, indicating that the latent representations encode uncertainty relevant to task outcomes. This supports the potential of modeling VLA with a dual-system perspective: fast, high-level alignment from textual goals to actions, and slow, generative simulation for dynamic risk estimation.
The left panel visualizes failing cases (left) with misaligned generated video clips and corresponding successful cases (right) with accurate predictions. The middle panel shows the confusion matrix of our human evaluation. The right panel showcases the PCA result of the single-step predictive visual feature. |
@article{chi2025_2506.18897,
title={ MinD: Unified Visual Imagination and Control via Hierarchical World Models },
author={ Xiaowei Chi and Kuangzhi Ge and Jiaming Liu and Siyuan Zhou and Peidong Jia and Zichen He and Yuzhen Liu and
Tingguang Li and Lei Han and Sirui Han and Shanghang Zhang and Yike Guo },
journal={arXiv preprint arXiv:2506.18897},
year={ 2025 }
}